


Author : Evermethod, Inc. | October 28, 2024
.png/preview.png?t=1721195409615)

.png?width=964&height=426&name=ELT%20(1).png)
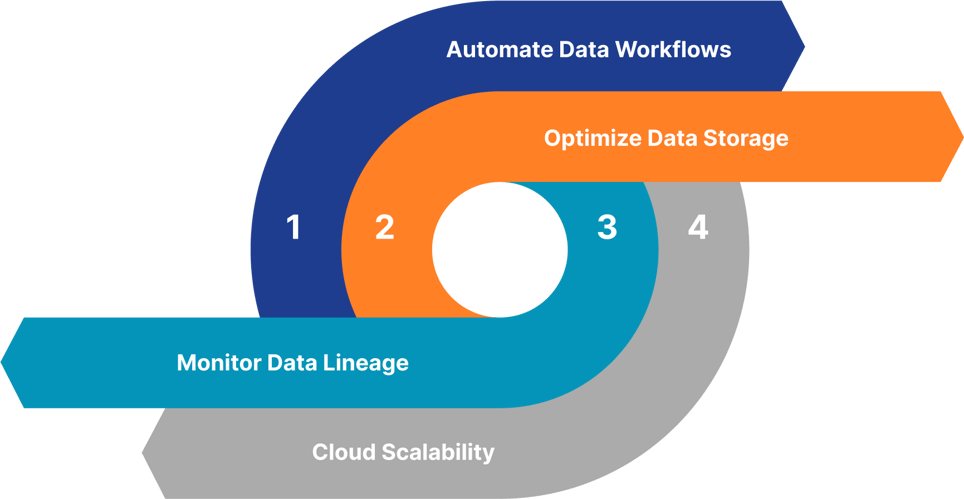
 Automate Data Workflows
Automate Data Workflows
Automation removes human error and optimizes repetitive data processing tasks. Optimize Data Storage
Optimize Data Storage
Using a combination of data lakes and warehouses to balance the storage needs for structured and unstructured data.
 Monitor Data Lineage
Monitor Data Lineage
Understand how data evolves using data lineage. This activity ensures compliance with regulatory requirements. Cloud Scalability
Cloud Scalability
Leverage cloud-native scalable solutions that can be optimized based on performance.
%201.png?height=70&name=development%20(1)%201.png) Set Up Validation Rules:
Set Up Validation Rules:
Use automated checks to flag and correct inconsistencies during ingestion and transformation.
 Embed Data Governance:
Embed Data Governance:
There should be governance frameworks for the entire organization to ensure data is processed safely in accordance with privacy standards such as GDPR or HIPAA.
 Monitor in Real Time:
Monitor in Real Time:
This kind of tool manages to track issues in a timely manner so that they can be resolved as soon as possible.
%2013.png)


